
As explained previously, we are working on an Observatory of Precarity in the Cultural Sector in Spain. The Observatory is thought of as a dynamic platform that shows metric data regarding current worker conditions and provides more visibility to the problem of precarity for cultural workers. At the same time, it allows users to create networks with each other and reach out to help entities after posting their public denouncement. Thanks to blockchain technology, the platform will be transparent and harder to censor. In this post we introduce the starting point we are going to use for the Observatory prototype and we present its architecture. Some features might be included or excluded in the following months, therefore some components might change but the main idea is still valid and worth sharing. So let’s dive into it!
Tecnology Stack
The main frameworks and libraries used in this prototype are:

Fronted
– React.js: this project was bootstrapped with [Create React App].
– [Material-UI]: for UI components.
– [Ethers.js v5]: for web3 interactions.
– [useDapp]: provides useful react hooks for blockchain interactions.
– [Apollo client]: to interact with The Graph network and our backend.
– [GraphQL]: as the data transfer layer replacing traditional REST API’s.
Backend
– [Apollo server]
– [Prisma]: node.js ORM to manage your db.
– [Nexus]: Declarative, Code-First GraphQL Schemas for JavaScript/TypeScript
– [GraphQL]: as the data transfer layer replacing traditional API’s.
– [PostgresQL]: open-source relational database.
Blockchain
– [Ethereum]: blockchain 2.0 network.
– [Solidity]: programming language for developing smart contracts in the Ethereum blockchain.
– [Hardhat]: development tools to develop, test and deploy smart contracts.
– [Waffle]: testing library for smart contracts.
– [The Graph]: decentralized service for indexing complex events in the blockchain.
Deployment
The backend of the project has been containerized using [Docker-compose].
Overview

At the blockchain level we will have a smart contract to register the cases reported by users. The task of this contract is to abstract common characteristics of reports as well as the details of each case and to serve as a registry with permissions, events, status variables, etc. This smart contract will issue events, which will be registered by The Graph nodes which will process each event for client requests.
At the backend level we have implemented a microservices architecture following the separation of concerns pattern. An API gateway has been designed with this purpose using GraphQL Tools Schema Stitching library. The microservices implemented by now are; the accounts service, the report service and the The Graph service (in test environment for now). For the backend services we use an Apollo server with a GraphQL API and Prisma ORM. By implementing this hybrid architecture we can progressively migrate services from web 2.0 to web3. We think this strategy, rather than reimplementing apps from scratch, is the way to go if mainstream services are to be migrated to web3.
Finally, at the frontend level we have a React web app which is an Apollo client. We make use of contexts and react-query to handle local and remote states. For routing within the app we use react-router and react-router-dom. The UI components are designed with material-ui, recharts and leaflet for the interactive map. The web3 stack is ethers.js with a useDapp framework, which is under testing.
Front-end discussion
¿Redux or not?
There are several ways to implement a react webapp, different architectures and tech stacks to handle the client state. Redux it’s a very popular library used to handle the app state through the combination of the following patterns: a store and a reducer. It is a powerful architecture but since we are prototyping it may not provide the desired flexibility. ([GraphQL & Redux]).
The Provider Pattern
Another way to manage the app state is through the use of contexts from the react library. A react context creates an immutable object that can be updated through the createContext function. It also has a provider and a consumer interface. The provider sets the state of the context, it can be placed in any part of the component tree but only the child components can make use of the consumer interface ([useContext hook]) to get the context. A great review of this pattern can be found in the article [React Architecture: The React Provider Pattern by Morten Barklund]
Back-end discussion
Hybrid Architecture
One of the main goals of this prototype is to provide a progressive adoption of the web3 technologies by the end user. Then why would our backend need a web 2.0 architecture?
Since we want to provide our users with web 2.0 UI’s we need to handle things in the backend so they don’t have to worry about transactions, wallets, etc. But this doesn’t mean we need a hybrid architecture since we could be using only web3 technologies in our backend. The main benefit of using a hybrid architecture is the flexibility given by the fact that we can offer the same service to the user whether it is web 2.0 or web3. This means that if we want to use an authentication service developed by us with a modern web 2.0 stack we could provide it and later on add the same service using blockchain solutions.
Monolithic API vs. Microservices through API gateway/proxy
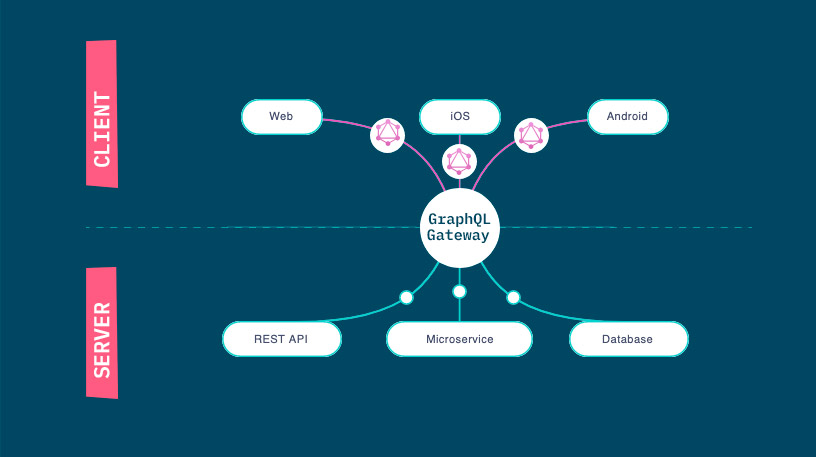
The question is: should we keep just one backend server with all the services or should we break it down to multiple servers applying the separation of concerns pattern?
A monolithic approach is faster to develop and can be clean if the resolvers become separated in different files. Whereas a microservices architecture ensures scalability and a cleaner way of integrating multiple third party services to the client.
This last point “cleaner way of integrating multiple third party services to the client” seems contrary to the web3 paradigm where clients tend to be “more autonomous” and it should be the user who decides which third party service to use. With this prototype we are questioning the approach to web3 adoption since a big issue with UX has been proved in the onboarding of new web3 adopters.
Moreover, the microservices architecture gives us the flexibility to migrate web 2.0 services to web3 technologies progressively, which is a great advantage when working with organizations. Therefore, the microservices architecture with a single entry point for the backend seems better for web3 adoption (simpler client).
GraphQL vs REST API
When implementing an API, what query language/protocol should we use? In this prototype we have chosen GraphQL for two reasons. The first because it’s faster to iterate with it since we don’t need to create multiple endpoints based on our needs, we just need to write new requests. This property of non-versioning in GraphQL provides great flexibility when prototyping. The second reason for our choice is that it is a relatively new technology worth trying and that, although it’s adopted less and less secure than REST, might lead to greater scalability in case the prototype raises public interest. Find a good review of pros and cons of these implementations of API in these articles; [GraphQL vs REST: 4 Critical Differences by Amit Phaujdar] and [GraphQL is the better REST]
Federation services vs Schema stitching
What is shema stitching?
When implementing microservices architecture through an API gateway we can find a solution provided by [GraphQL Tools] called schema stitching. This library implements a GraphQl gateway to integrate multiple schemas into a unique endpoint.
What is a federation service?
Another popular solution to GraphQL gateway is [Apollo Federation]. This solution, which might seem a great choice at first glance, comes with a big dependence on the Apollo Studio service which provides a cloud platform for subgraph development in a collaborative way along with a supergraph composition automation service.
Quoting [Schema stitching Handbook]:
“As you get the hang of schema stitching, you may find that Federation services are fairly complex for what they do. The buildFederatedSchema method from the @apollo/federation package creates a nuanced GraphQL resource that does not guarantee itself to be independently consistent, but plugs seamlessly into a greater automation package. By comparison, stitching encourages services to be independently valid and self-contained GraphQL resources, which makes them quite primitive and durable. While federation automates service bindings at the cost of tightly-coupled complexity, stitching embraces loosely-coupled bindings at the cost of manual setup. The merits of each strategy are likely to be a deciding factor for developers selecting a platform. Stitching is a library used to build a framework like Federation.”
Conclusions and future work
As you can see, the prototype builds upon multiple cutting-edge technologies which is already providing us with the opportunity to explore the growing ecosystem of web 2.0 and web3. It is also a very flexible and scalable architecture which means that any extension of the prototype could be easily integrated, this is important due to the research environment in which it is being developed.
The next steps in our road map are the design of the UI and the implementation of the defined features. Stay tuned!
SHARE
AUTHOR

![]() Authorship is by Luis H. Porras, but this content has been made by the whole P2PModels team
Authorship is by Luis H. Porras, but this content has been made by the whole P2PModels team ![]()
![]() Images are by Elena Martínez
Images are by Elena Martínez
![]() Copy editing is by Tabitha Whittall
Copy editing is by Tabitha Whittall
![]() Rosa Chamorro and Samer Hassan make everything is posible
Rosa Chamorro and Samer Hassan make everything is posible


